

{kind=link}
The RX 9070 is positioned to combat the RTX 5070, with the 9070 XT up towards the 5070 Ti. AMD has determined to steal NVIDIA’s naming this time, rising bored with the naming scheme that introduced us the R9 270, R7 370, RX 480 (watch our assessment), Fury, Fury X (watch our assessment), RX 580 (watch our assessment), Vega Frontier Version (watch our assessment), Vega 56, Vega 64 (watch our revisit), again to RX 590 (watch our assessment), Radeon VII (watch our assessment), RX 5700 XT (watch our assessment), RX 6950 XT (watch our assessment), and RX 7900 XTX.
Possibly leaving the previous names behind is for the very best. We stay up for seeing what they do once they hit the dreaded “10.” Possibly AMD would be the first to deliver us the ten,080 Ti…XT.
Overview
First up, the worth: At $50 aside, it looks like these playing cards will smother one another. Till we will publish take a look at information, we received’t know which one will cannibalize the opposite — but it surely appears probably, as occurred with the 7900 XT and 7900 XTX once they have been about $100 aside at launch.
A fast pricing recap:
AMD’s RX 7800 XT is presently priced at round $500 to $530 relying on the place or if you will get it. The RX 7900 GRE has been round $550 (although has been largely out of inventory recently). The RX 7900 XT is principally gone, however was round $630 to $640 on the finish of final 12 months and extra generally round $680. The 7900 XTX was as little as $800 to $820 in November and was generally $930 in January. It launched at $1,000.
The 7900 XT obtained a assessment from us entitled “AMD’s Grasping Upsell” in December of 2022, knocking it for the $900 worth level. We revisited it in October of 2023, so lower than a 12 months later, since you might get some fashions for $720. AMD dropped the worth by 20% or so in lower than a 12 months.
The 7900 XT grew to become an superior worth after the worth drops at the very least for a window there, particularly in raster efficiency.
We’ll speak extra in regards to the pricing as soon as we now have benchmark numbers in. That’ll embody NVIDIA’s lineup.
With that context, let’s get into the specs of the 9070 and 9070 XT.
Specs

AMD offered this spec sheet for its RX 9070 and RX 9070 XT. The RX 9070 could have 56 Compute Models, or CUs, towards the 64 on the 9070 XT (a 14% improve in CUs). AMD has finished splits like this earlier than, like Vega 56 and 64, however the structure has modified dramatically since then.
In a name with the press, AMD claimed that the explanation it didn’t go as much as one thing like 80 CUs is as a result of it didn’t need to make one thing tremendous costly. That positively would have been very costly. It could have been a bigger die so that’s correct that the prices would go up. We additionally suppose that the structure may simply wrestle to compete with a 5090 on the value they would want to hit to take action and that’s most likely a big cause for this as effectively. AMD is specializing in the mid-range, the place the structure is maybe higher tuned to compete.
The {hardware} ray tracing accelerators match the CU depend at 56 and 64, with AMD’s so-called “AI accelerators” at 112 and 128 models.
Enhance clocks are considerably totally different between them: The 9070 XT is ready to make extra use of its additional 84W of energy funds to hit an marketed enhance of two.97 GHz, with the RX 9070 non-XT at 2.52 GHz (the unique slides mentioned 2.54, however AMD introduced that down earlier than announcement). Reminiscence capability is an identical between them at 16 GB. Each playing cards will make the most of GDDR6 at 20 Gbps. Board energy is marketed at 220W and 304W, hopefully with room for board companions to scale up with overclocking help. NVIDIA’s OC help has been comparatively lackluster this era, regardless of what the corporate claimed. Hopefully AMD could make it thrilling.
Lastly, the playing cards technically are on PCIe 5.0 x16 slots, however we already confirmed that there’s no actual impression to efficiency right here regarding the 5090. There virtually definitely received’t be any impression with the 90 collection both with the exception in the event that they have been to chop down the slot on a lower-end mannequin or one thing, however for this, it received’t matter. DisplayPort is as much as 2.1a and HDMI at 2.1b.
Block Diagram

Right here’s the block diagram for the RDNA 4 die and structure. AMD famous that this identical die shall be used for the 9070 and 9070 XT. The corporate says this shall be 356.5mm^2, include 53.9 billion transistors at most, and run on a 4nm course of node. After which the 9070 would have among the CUs principally turned off. AMD says that that is monolithic silicon and never a chiplet design.
This variation of the GPU has 4 Shader Engines, inside every is contained 8 dual-compute models. L2 Cache is centralized and situated in the direction of the center of the logical block, totaling 8MB max of L2, with 64MB of infinity cache on the outer edges and nearer to the reminiscence controllers.
AMD’s huge declare here’s a renewed give attention to ray tracing efficiency, the place it says it has doubled ray intersection charges and improved ray traversal, alongside adjustments to the way it’s dealing with bounding packing containers for BVH probing. This can be a huge focus for AMD this era and it’s someplace the corporate must focus as a result of they’re fairly aggressive in raster in comparison with NVIDIA numerous the time, however there’s cases the place they get utterly crushed in ray tracing.
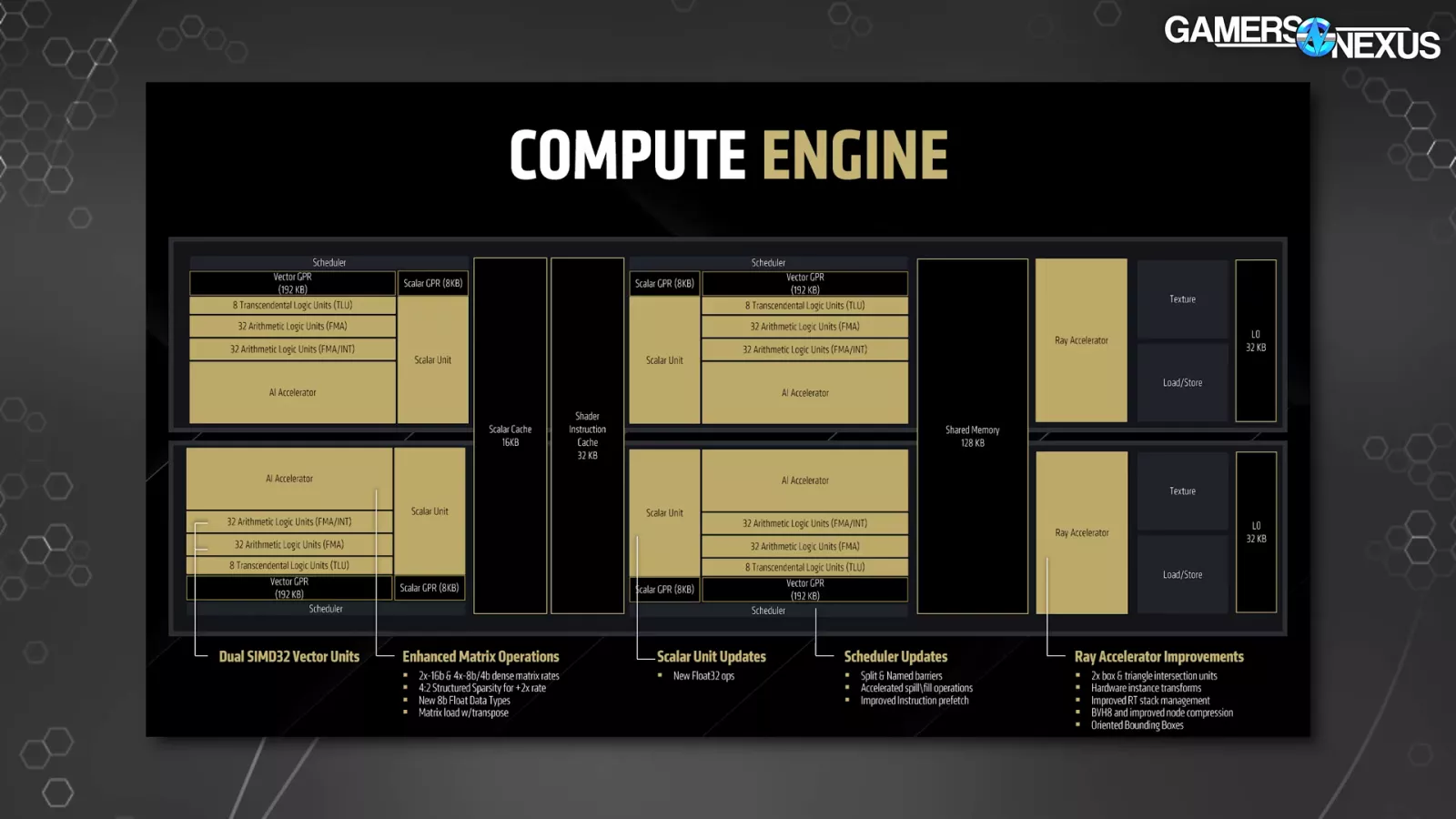
Right here’s a better look internally. The realm we’ll focus is on RT. Inside what AMD calls the compute engine, AMD now has 2x ray accelerators to deal with field and triangle intersections. AMD famous that the second intersection engine inside the accelerator “doubles the efficiency for each ray-box and ray-triangle testing” over RDNA 3, though do not forget that this doesn’t imply a clear doubling in efficiency in an precise ray tracing recreation state of affairs. AMD famous that RT processing takes benefit of a 128KB shared reminiscence block, additionally proven right here.

This slide was devoted to RT enhancements particularly and highlights the addition of AMD’s devoted ray rework block, which it says will “offload transformation as you transition from the top-level RT construction to the underside stage, the place there could also be many cases of a specific geometry.” Beforehand, shader directions dealt with this process and, AMD says, added overhead to ray traversal which it claims to now have eradicated.
The ray accelerators have the ray rework block and two intersection engines, which themselves required adjustments to BVH dealing with to be absolutely leveraged.

AMD mentioned it’s transferring to an 8-wide BVH resolution from a 4-wide possibility on earlier {hardware}, which it {couples} with its new oriented bounding field method that makes an attempt to scale back wasted, empty house in bounding packing containers by higher conforming to the geometry within the scene, theoretically decreasing false positives and in addition decreasing efficiency overhead and loss throughout geometry intersection probing.
The slide claims that traversal efficiency improves by 10%. Once more, this isn’t a literal 10% achieve within the closing framerate in an RT recreation, however is a constructing block in a collection of others to contribute to AMD’s claimed uplift.
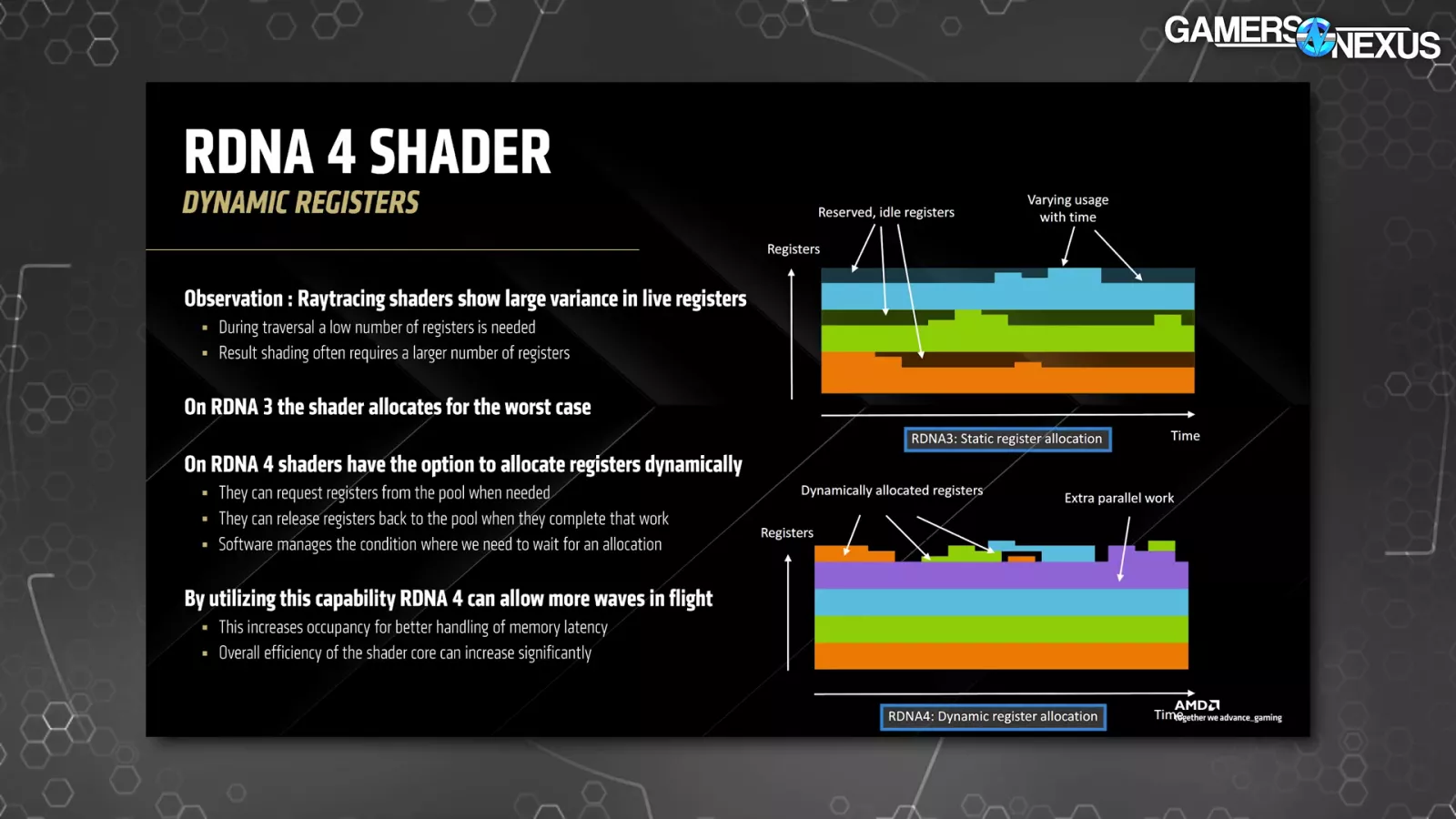
This slide above was fairly cool. The fitting facet exhibits AMD’s register allocation, with the top-right exhibiting RDNA 3 and the bottom-right exhibiting RDNA 4. Between the 2, there’s a change from static allocation in RDNA 3 to dynamic in RDNA 4. AMD highlights that RDNA 3 would reserve registers which might not be put to work, so it’d maintain them in case they have been wanted, probably not want them, and find yourself with inefficiency and unavailable sources. RDNA 4 is attempting to resolve this. The bullets on the left make all of this gorgeous clear, stating that the development is in environment friendly utilization, largely as a result of registers will be launched or requested as wanted.

AMD is claiming that its RDNA 4 CUs enhance traversal by 2x over RDNA 3 when iso clock and bandwidth. The 3D block within the picture is meant to roughly illustrate the place AMD thinks it’s discovering most of its efficiency: It seems that the 2x intersectors and BVH8 change (from 4) are the most important contributions.
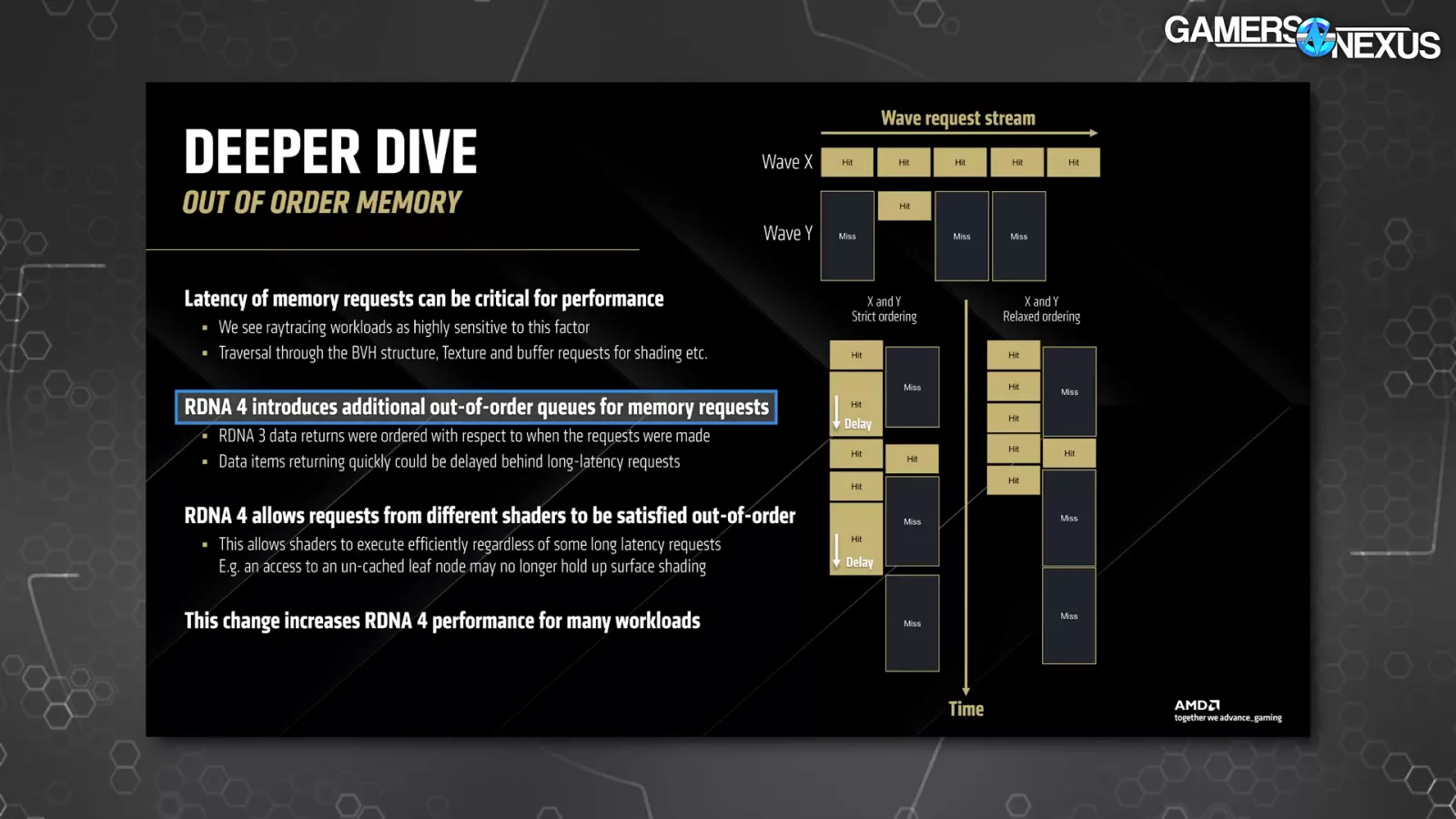
RDNA 4 additionally introduces extra out-of-order queuing and goals to scale back latency of reminiscence requests, which AMD claims additional profit RT efficiency. Additional out of order execution permits work to finish even whereas longer latency requests are processing or queuing. AMD makes an instance out of an uncached leaf node on the slide above, which might include the bottom stage of element in an RT workload and will in any other case maintain up a scene.
First-Social gathering Claims

First-Social gathering Claims: RX 9070
Let’s get into the first-party benchmark claims subsequent. We received’t spend a ton of time on these because you’ll be capable to discover loads of third-party critiques quickly sufficient, however it should assist set expectations for what AMD is concentrating on.

AMD’s fast reference slide exhibits a claimed 26% uplift towards the RTX 3080 and 38% uplift towards the 6800 XT. AMD didn’t present something from NVIDIA’s 40 or 50 collection right here.
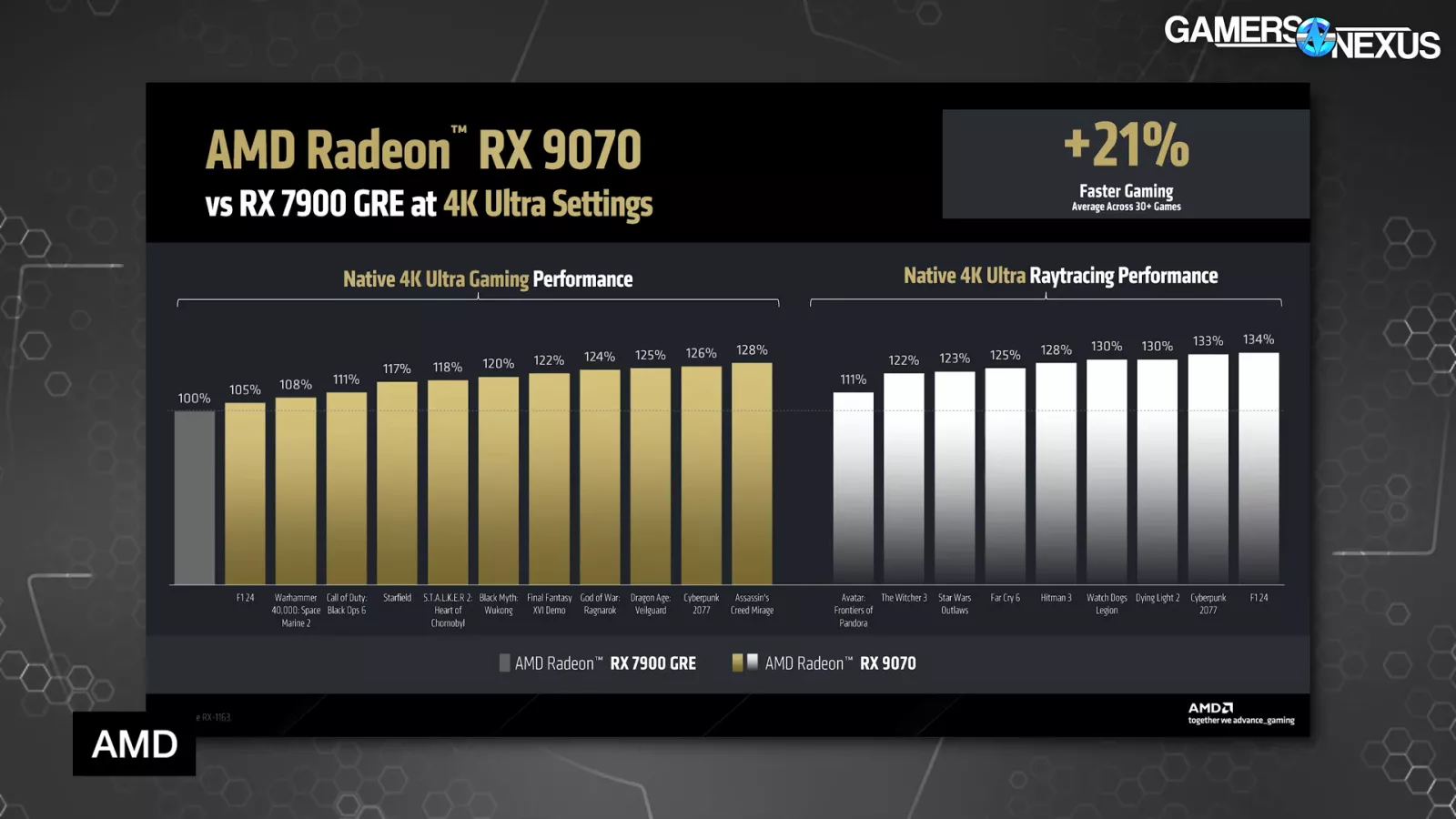
At 4K/Extremely and with out upscaling, AMD is advertising the RX 9070 non-XT as a median of 21% improved over the RX 7900 GRE. The 7900 GRE was initially a $550 card. AMD is exhibiting non-RT efficiency as bettering as much as 28% on baseline 100%, with the ray tracing efficiency exhibiting a disproportionately favorable achieve to the brand new structure at as much as 34%. That is good for AMD, because it was weakest in ray tracing traditionally. This disproportionate achieve received’t wipe-out AMD’s deficit in one thing like Cyberpunk 2077 or presumably Black Delusion: Wukong, however the important thing shall be whether or not it will probably shut the hole with higher worth.
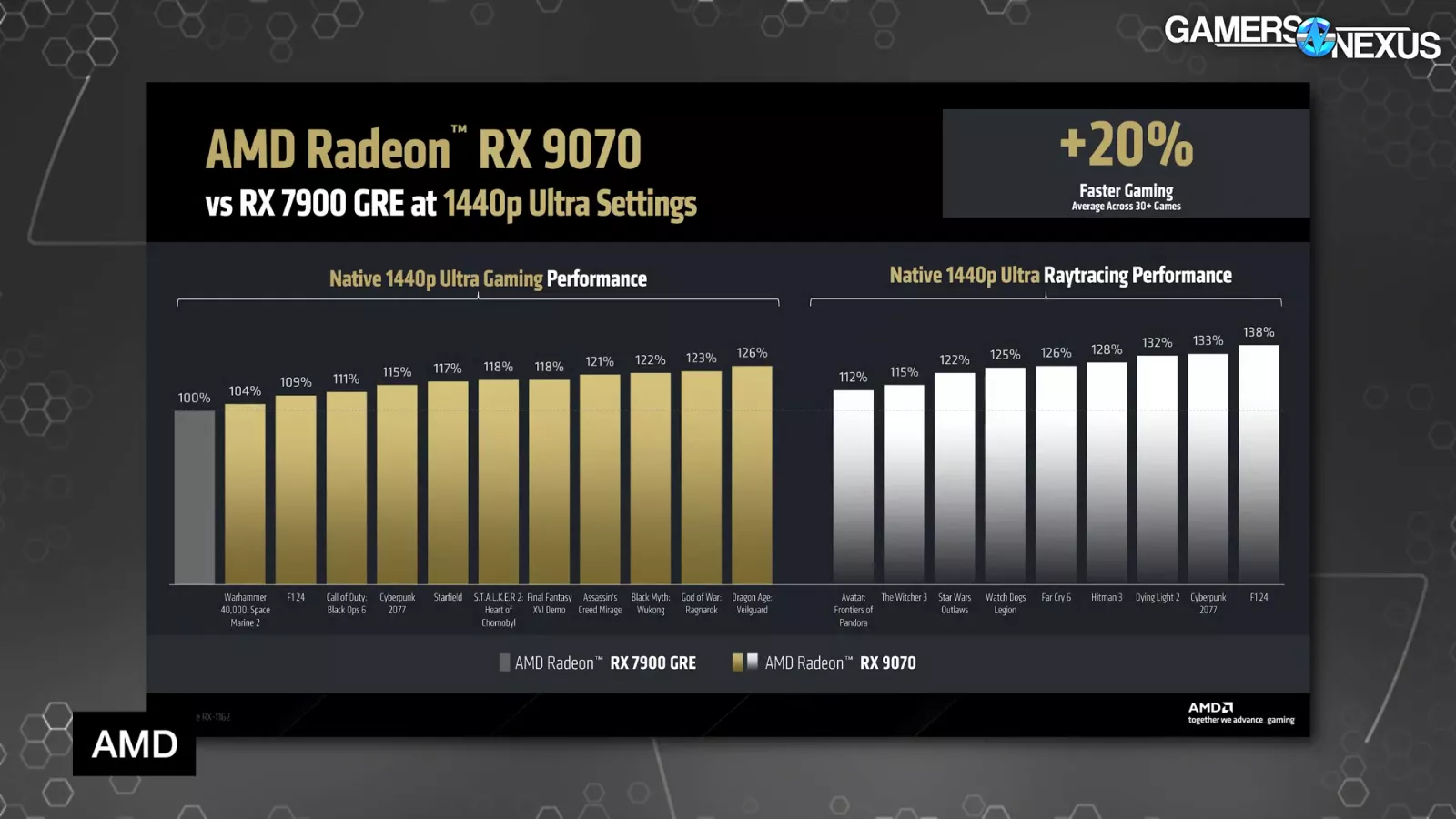
At 1440p/Extremely and native, AMD claims the 9070 shall be 20% quicker on common, with the height at 38% improved for ray tracing and 26% improved for raster. AMD noticed a barely bigger enchancment in RT at 1440p for F1, which is attention-grabbing, regardless of general losses in scaling in raster. 4K diverging from 1440p isn’t irregular, although. One factor we do need to name consideration to and provides AMD credit score for right here although is that they’re exhibiting native efficiency. Even when they present FSR, that’s positive in the event that they stored it locked to the identical FSR choices between their older and newer gen playing cards in the event that they’re evaluating their very own merchandise to one another; exhibiting native is a greater step than that. This can be a large enchancment over what we’ve been complaining about NVIDIA doing, which was evaluating its 50 collection to its 40 collection and enabling MFG 4X on the 50 collection however not the 40 collection after which simply making it appear to be they’re wildly higher than they really are. So we do need to name consideration to and provides AMD credit score for making a extra honest head-to-head comparability between its personal merchandise right here somewhat than enabling some particular multiplier on one and never the opposite.
First-Social gathering Claims: RX 9070 XT

As for the RX 9070 XT, AMD in contrast it towards its 6900 XT and NVIDIA’s RTX 3090, once more missing in any 40 or 50 collection comparisons right here. It claims a 51% uplift over the 6900 XT and 26% common uplift over the RTX 3090.
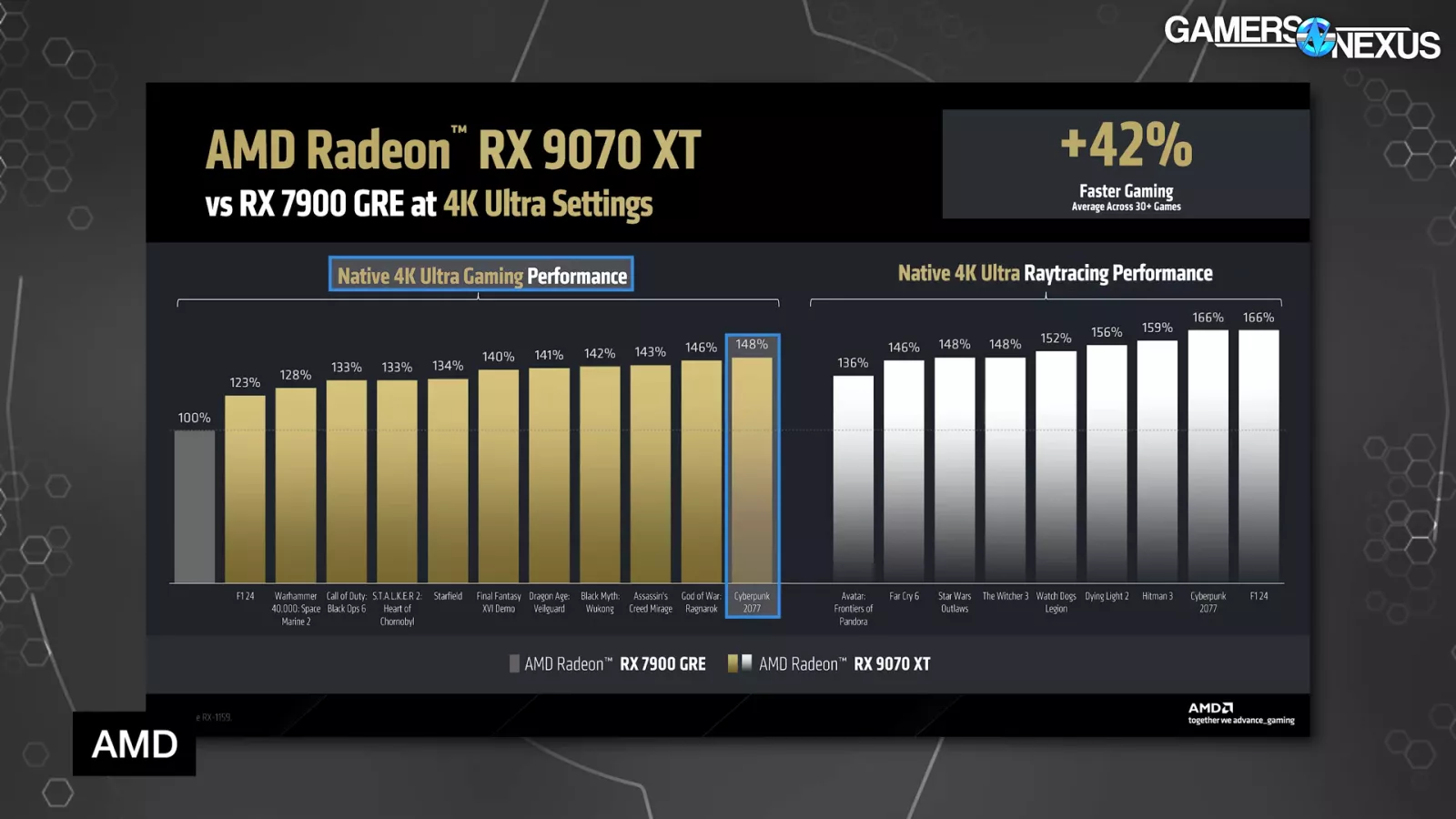
In opposition to the identical 7900 GRE, AMD claims a median uplift of 42%, or 66% in F1 24 with ray tracing on the excessive finish. AMD claims it noticed the identical uplift in Cyberpunk with RT. In raster efficiency, the good points max-out at 48% over baseline.
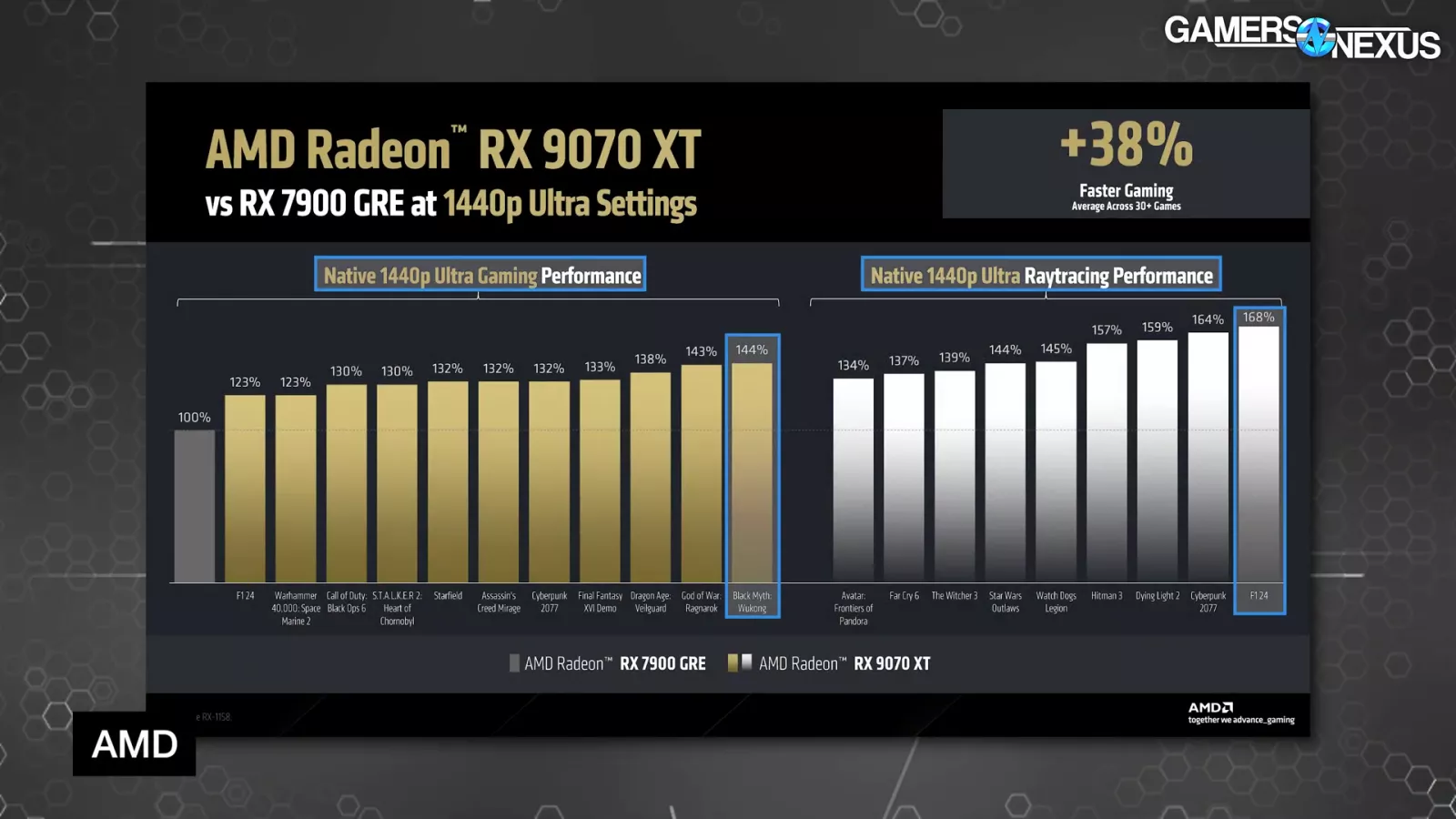
At 1440p, AMD is seeing decrease general common uplift, with a slight uptick in F1 24 with ray tracing.
Conclusion

We might run these p.c scaling enhancements towards our personal numbers to approximate the place AMD would land since we now have all the main points we want right here to calculate the anticipated efficiency. Launch is just a few days away although, and we’d somewhat take a look at the playing cards than extrapolate on information that we now have no management over or perception into. We’ll have third-party numbers in our personal critiques quickly sufficient.
Pricing goes to stay the important thing concern for these playing cards. AMD is doing a little attention-grabbing issues architecturally. We’ve coated a little bit of that on this article. AMD has loads of alternatives to have…ROPs and cables that…should not going to burn. The sphere is ready for AMD to have a victory right here. It’s as much as the corporate to execute on it. We simply made a video known as “AMD, Don’t Screw This Up” that talks primarily in regards to the pricing, however the cause AMD has this superb alternative is due to NVIDIA’s screw-ups.
Pricing is the important thing concern, however we’ll withhold judgment on it till we assessment it a few week from now.
From what we perceive, it seems like provide shall be okay, but it surely’s arduous to know what that actually means.
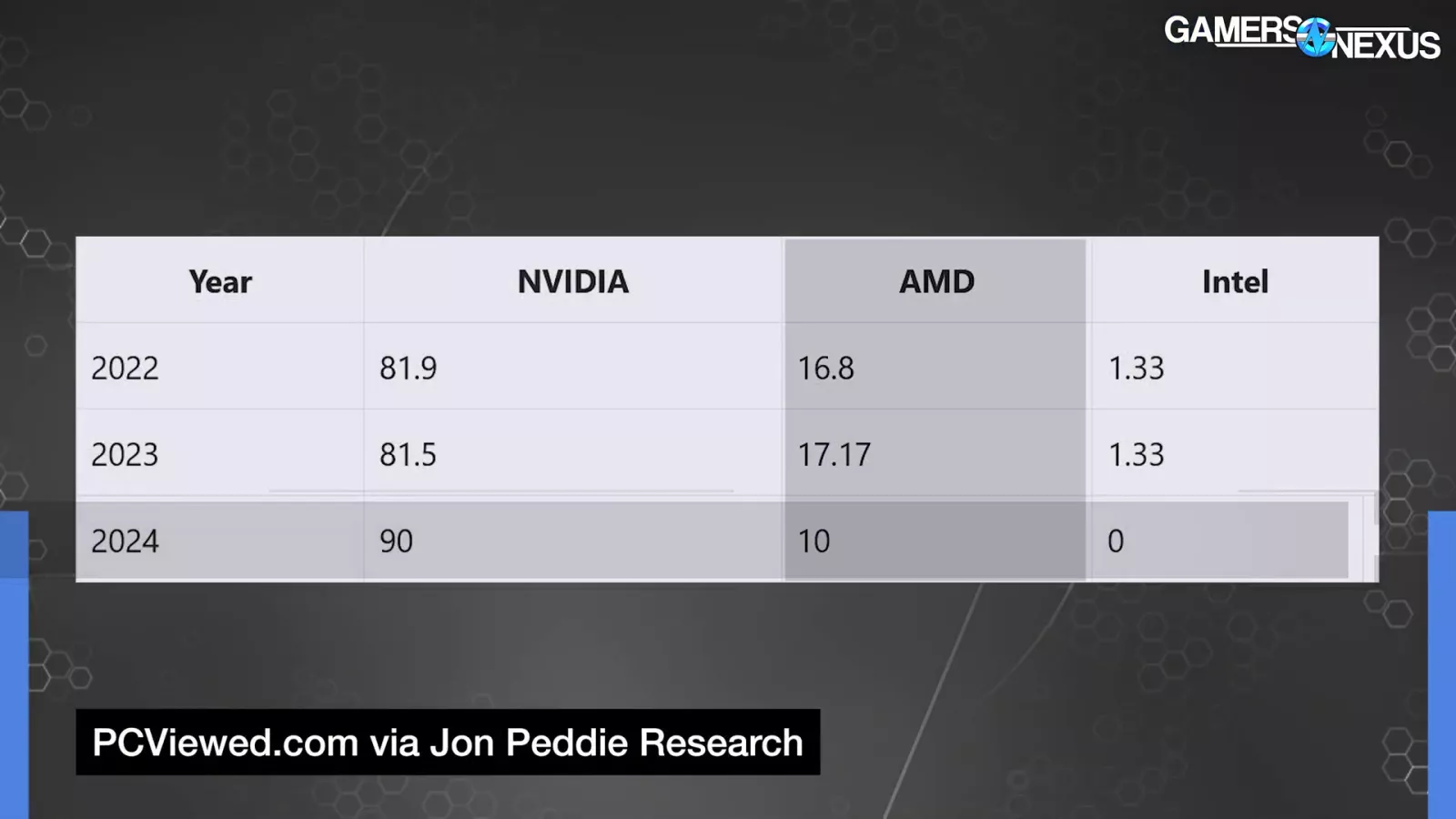
AMD actually wants to realize market share. In accordance with Jon Peddie Analysis, AMD is near the bottom they’ve ever been within the GPU market at round 10 p.c whereas NVIDIA is down when it comes to popularity and belief of their model, so now’s the time for AMD to strike. We’ll let in the event that they execute on that quickly.