
{kind=link}
![]() Qualcomm is lastly speaking concerning the tech of their CPUs with the brand new Snapdragon X2 Elite Excessive CPUs. SemiAccurate likes the tech and silicon lots however the ultimate product isn’t actually purposeful.
Qualcomm is lastly speaking concerning the tech of their CPUs with the brand new Snapdragon X2 Elite Excessive CPUs. SemiAccurate likes the tech and silicon lots however the ultimate product isn’t actually purposeful.
Authors Observe: It is a huge story, longer than I’ve executed in years so will probably be damaged up into items and posted within the coming days. If it appears a bit destructive at first, that’s solely the start, and finish, the huge center is the tech and we like that lots. That is Half 1 of a sequence. Half 2 could be discovered right here, Half 3 could be discovered right here, and Half 4 could be discovered right here.
Overview and Historical past:
Qualcomm has been making PC CPUs for over a decade with, lets be charitable, blended outcomes. The reference SemiAccurate discovered after nearly a number of minutes of looking is right here in 2012. Ignore these early makes an attempt at making an ARM based mostly Home windows laptop computer, aka WART or Home windows on ARM RT. What we try to level out is this isn’t a brand new program, it’s 10+ years in, and that’s essential to think about when evaluating the top product, not the silicon. We are going to do each.
Final summer season the belated Snapdragon X Elite CPU got here out and the silicon was actually good, the Nuvia acquisition delivered on the promise. SemiAccurate favored the silicon however discovered the platform as an entire unacceptable. Why? We acquired a pattern the day after launch, a Microsoft Floor Laptop computer. It flat out didn’t work. After dozens of hours of attempting to get this system to a state the place it did one thing stably, we gave up getting no additional than a boot loop.
When Qualcomm requested us what we needed to to check, we instructed them we had been going to strip Home windows off and set up Linux, then see what the expertise was like. About six weeks in the past we lastly acquired the system to the purpose the place it will load a desktop and open a browser. In the event you moved the mouse wheel, the trackpad and lots of different issues had been MIA, the entire system crashed. We have now since gotten our arms on an Acer Swift 14 and had a a lot better expertise, so long as issues like sound and afew different bits will not be in your performance guidelines however, nicely, that is only some days in.
Earlier than you click on away as a result of Linux or us not operating Home windows, it’s related to you even in the event you run Home windows. Why? As a result of Qualcomm’s software program enablement is one thing between non-existent and antagonistic to builders no matter OS. After a decade plus of labor, these WARTBooks will not be near functionally suitable with the x86 Home windows software program base. You probably have an issue with the gadgets, good luck to you.
A few 12 months in the past, Dell and Microsoft went on a gross sales name to an in depth relative who works at an engineering agency. The presentation was pushing WARTBooks arduous, and to be blunt, the duo outright lied to the client. How do we all know? He was texting me the entire time reality checking presentation claims. They claimed the compatibility with x86 software program was 82%, probably larger now. I requested him to get a replica of the presentation so he might take a look at the fantastic print about what that 82% encompassed. They declined. Additionally they declined to reply the query straight. And so they lied about what Intel was releasing and when. This isn’t a Qualcomm fault, it simply illustrates the woeful state the gadgets had been in about six months after launch.
The true kicker was when my relative requested about administration. Why? As a result of I requested him to. Qualcomm X Elite programs don’t have any {hardware} administration, no vPro equal. The duo claimed this wasn’t obligatory and software program might do all the things, nobody wanted {hardware} administration anymore. I don’t assume my relative would discover the humor in flying out to a bridge constructing venture in rural Oman to reimage a useless laptop computer. On the brilliant aspect, this has been addressed within the Snapdragon X2 Elite Excessive CPUs, extra on that a lot later.
Ultimately, the present model of the Snapdragon X Elite CPU is strong silicon however the gadgets they go in to are merely unacceptable. They aren’t laptops, they’re massive telephones, they usually simply don’t work proper. There isn’t any software program assist, distributors lie for gross sales, and Qualcomm exhibits no signal of addressing the state of affairs. Will issues change with the brand new Snapdragon X2 Elite Excessive CPU? Based mostly on conversations had with dozens of Qualcomm individuals final week, we extremely doubt it, however we hope to be pleasantly stunned. In the interim, keep away from the X Elite and anticipate impartial testing earlier than you add any X2 gadgets to your consideration record.
Earlier than we go on to the small print of the brand new platform, another factor to consider. Nvidia has now launched their N1X/GB10 gadgets, the Spark platform. It principally doesn’t work, the discharge was a PR stunt, and it’s priced to stupidity. That mentioned it’s a higher product than the Snapdragon X and X2 Elites. Why? As a result of the {hardware} could also be damaged however the software program assist is there. By the point the buyer gadgets ship, at present set for announcement after CES and availability in June-ish, issues shall be higher. Qualcomm has misplaced all the dev neighborhood to Nvidia, squandered a decade lead. No sane developer will have interaction with Qualcomm over Nvidia at this level, their antagonism over the previous 18 months has ensured that. Self-inflicted wounds like this are why we are able to’t advocate any Qualcomm laptop computer merchandise till we see direct proof of a change, and an enduring one at that.
The Platform:
On that joyful observe, on to the CPU itself, and it’s a good factor. The essential platform known as the Snapdragon X2 Elite Excessive with a lesser non-Excessive variant within the wings. Jokes abounded about ready for the Snapdragon X2 Elite Excessive Professional Plus Platinum before you purchase, at the very least Qualcomm shouldn’t be brief on suffixes, and might show it.

A protracted lengthy record of the small print to save lots of quite a lot of typing
The Excessive is an 18 core CPU with a 4 slice Adreno GPU whereas the non-Excessive SKUs have both 12 or 18 cores. These cores are divided into clusters of six that share caches and different buildings, are available two classes, Prime and Efficiency, however are in any other case comparable. Prime are the excessive finish cores, Efficiency are a extra environment friendly core however not a ‘small’ core within the cellphone sense of the time period small. Assume excessive finish and center, not excessive and low. It is a sensible choice, true small cores make nearly no sense in a laptop computer type issue with a laptop computer battery, telephones certain, massive system, no.
Prime cores clock to five.0GHz within the Excessive, one core at that clock per cluster, 4.7GHz within the 18C non-Excessive, and 4.7/4.4GHz within the 12C SKU. There are quite a lot of tips that Qualcomm did with the clocking, Cluster-Stage Multi-Stage Enhance (CLMLB – Rhymes with ‘orange’ whereas sliding off the tongue) is the primary one, however once more extra on that in a bit.

A Sadly Deceased X2 Elite Excessive
Reminiscence is the primary distinction between the Excessive and non-Excessive packages, however all use LPDDR5x. The Excessive gadgets have reminiscence on bundle, three stacks totaling 48GB on a 192b bus operating at a max of 9523MT/s. We had been hoping to see the magic 9527MT/s determine however Qualcomm allow us to down on this efficiency entrance. Sure that was a joke, the reminiscence is fairly rattling quick. All different gadgets don’t have reminiscence on bundle and solely use a 128b bus however theoretically run on the identical pace. If something about trendy CPU energy, the distant reminiscence SKUs will chew by way of much more power, and do it slower. Because of this in the event you go for any Qualcomm CPU, the Excessive is the one sane alternative. Or purchase an Intel Lunar Lake just like the one that is being written on, as a bonus, it additionally works proper each time.
The brand new gadgets additionally sport a brand new Adreno GPU, a brand new Hexagon NPU able to as much as 80 TOPS, a brand new Spectra ISP, Adreno DPU and VPU which helps 8K in {hardware}, and greater caches. The final degree cache is 9MB shared system reminiscence, the CPUs and GPUs every have their very own caches which shall be coated later.
Extra importantly is Snapdragon Guardian, the {hardware} administration system we referenced earlier. Due to this the system has express ties to both an X75 5G modem or a 4G mobile IOT modem which is a double edged sword. Once more extra on this once we go into particulars later nevertheless it has points and benefits.
Toss in connectivity by way of Wi-Fi 7 with 6GHz band assist, multi-link assist, and twin Bluetooth connectivity. There are additionally 3x 40Gbps USB4 ports, 12x PCIe5, 4x PCIe4, and SD card assist. The PCIe lanes can assist 2x NVMe drives leaving 4x lanes for an exterior GPU which Qualcomm says is feasible. Don’t maintain your breath to see a tool with one however technically it’s supported. General it’s a fairly strong set of I/O capabilities, nothing to complain about right here.
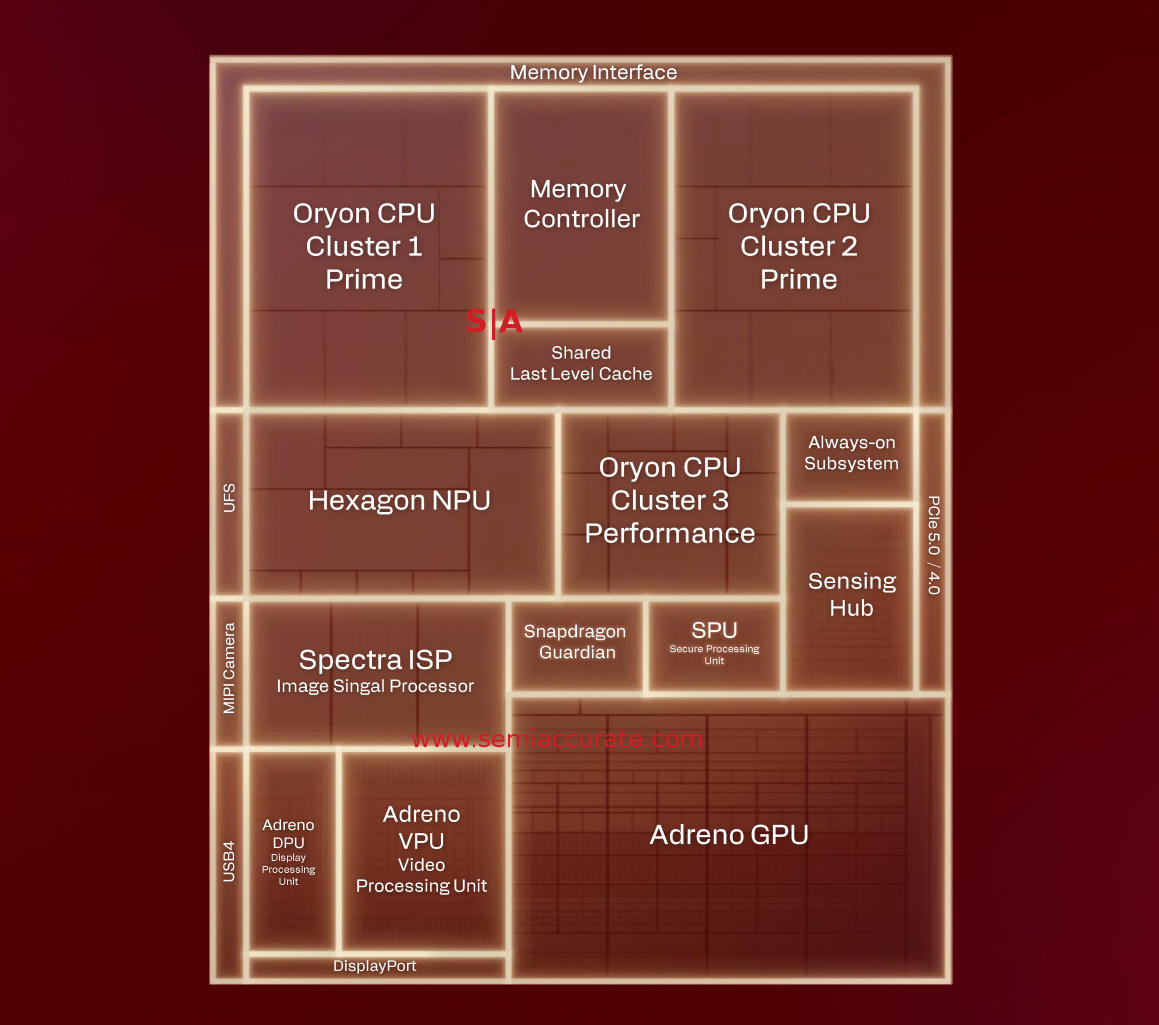
Block Diagram of the X2 Elite SoC
All of that is constructed on a TSMC 3nm course of, actual variant unspecified, which suggests it needs to be fairly environment friendly. The die dimension wasn’t formally disclosed however they did give us a pattern as a memento. As you may see above, there’s a little bit of epoxy on the sides however the die is about 220mm^2. Not unhealthy, Intel’s Lunar Lake is a twin die of 146mm^2 and 46mm^2 on TSMC N3B and N6 respectively, we don’t depend the 22nm interposer. General the brand new Snapdragon X2 Elite CPU is about what you’ll count on in most methods, however the particulars are the place it will get attention-grabbing.
The CPU Cores and Cluster:
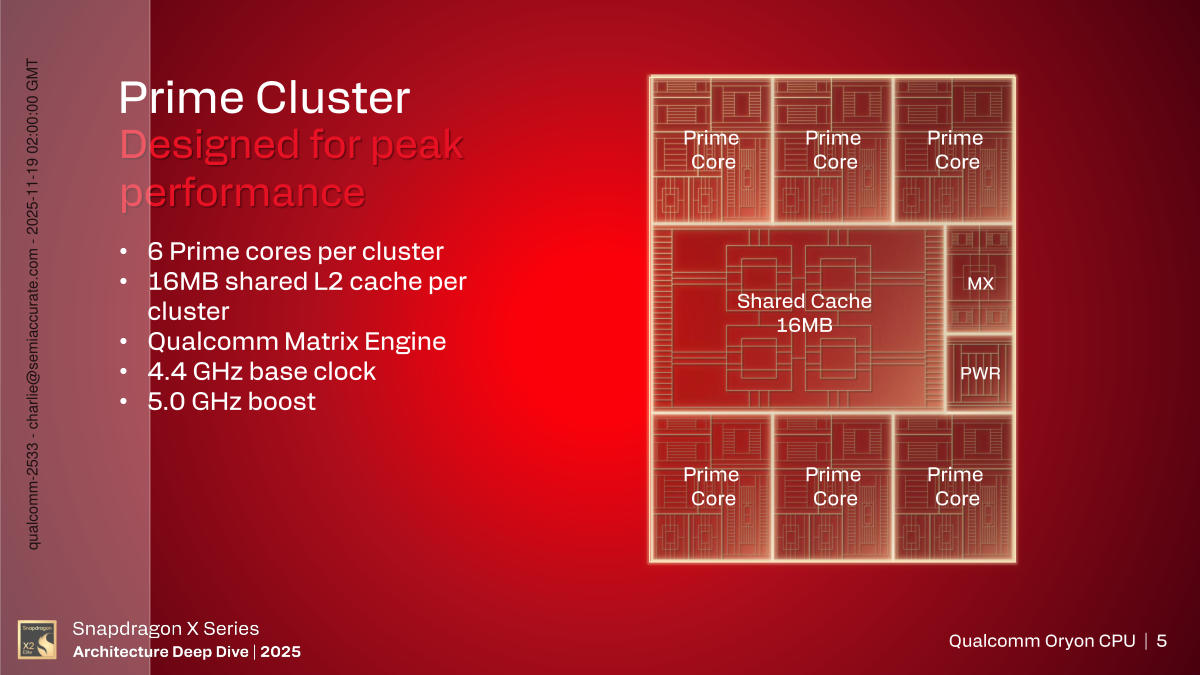
The Prime Cluster Format
The very first thing to speak about on the CPU aspect is the clustering. As we mentioned above, there are three clusters on this die, 2x Prime and 1x Efficiency, six cores every. The Prime cores have 16MB of shared L2 cache on the cluster, the 12MB for Efficiency, and all absolutely coherent. Each cluster varieties even have a Matrix Engine (ME) coupled to it. Extra on this later however simply notice there’s one per cluster even when software program sees it as one as a part of every core.
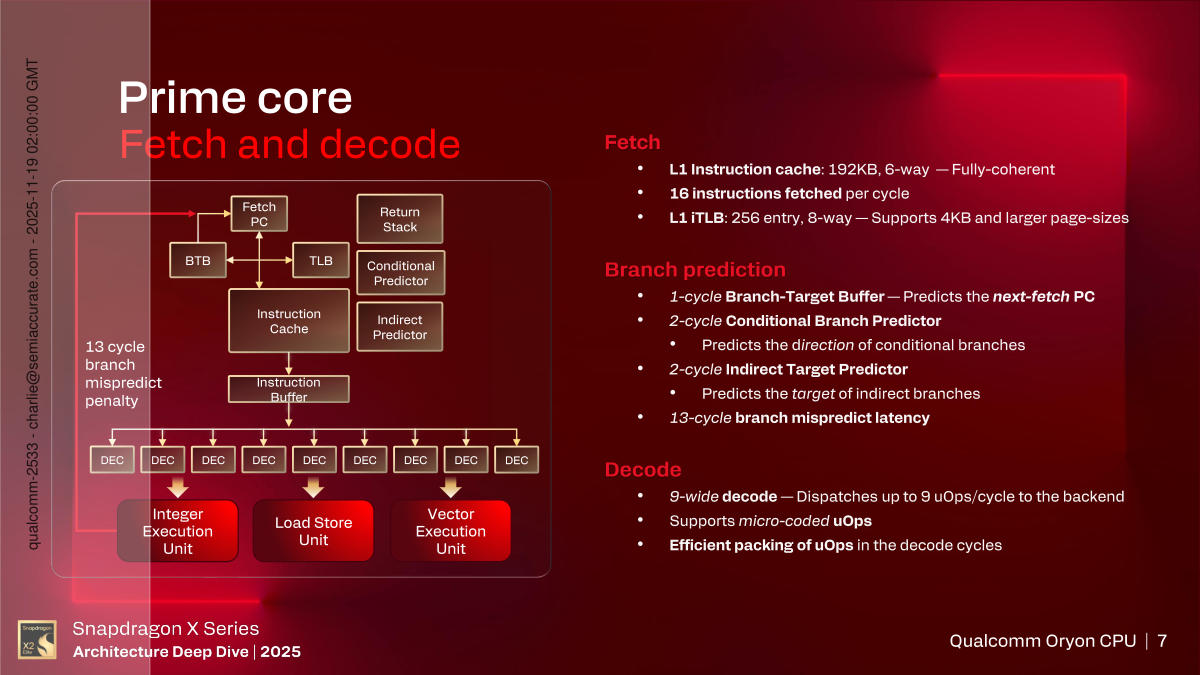
Prime Cluster Fetch and Decode
For the entrance finish, issues get fairly extensive fairly quick. Fetch is 16 directions per cycle, helped alongside by a 192KB L1I$, 6-ways and absolutely coherent in the event you care about these particulars. No L1D$ dimension was specified. The L1 iTLB is 256 entry with 8-ways and helps web page sizes from 4KB to 1MB. Fairly customary stuff to feed the extensive bits that comply with.
There are 4 department predictors, a 1-cycle for the BTB, a 2-cycle conditional department predictor, and a 2-cycle oblique goal predictor. Earlier than you level out that 1+1+1=3 not 4, there’s a fourth that was talked about however wasn’t absolutely defined, three are primarily used however a fourth exists. Mispredict penalty is 13-cycles and as you may see above, that every one feeds a 9-wide decoder.
As if by magic, there’s additionally a 9-wide register rename which completely matches the decoder width, coincidence or conspiracy? Jokes apart this isn’t something too out of the strange however it’s extensive, and there are separate bodily registers for every sort of register. The integer and vector models have 400+ registers for rename, every. Essentially the most attention-grabbing bit about this portion of the CPU is that it’s checkpointed so a department mispredict gained’t essentially imply a full flush with the attendant penalties, you may simply rewind it a bit and keep it up.
Different bits, the CPU now makes use of micro-ops and might dispatch as much as 14 a cycle to the reservation stations. That’s one every to the 6 integer, 4 vector, and 4 load/shops, plus none as a result of that might add to fifteen and there are solely 14. What do you assume that is, department prediction? And whereas we’re with reference to micro-ops, the X2 may also fuse them when wanted, and it helps reminiscence disambiguation. In case you’re questioning, I’m certainly getting flashbacks of the Pentium 4 briefings and it’s a bit disagreeable. Retirement is out of order with as much as 9 micro-ops per cycle with a 650+ entry reorder buffer.
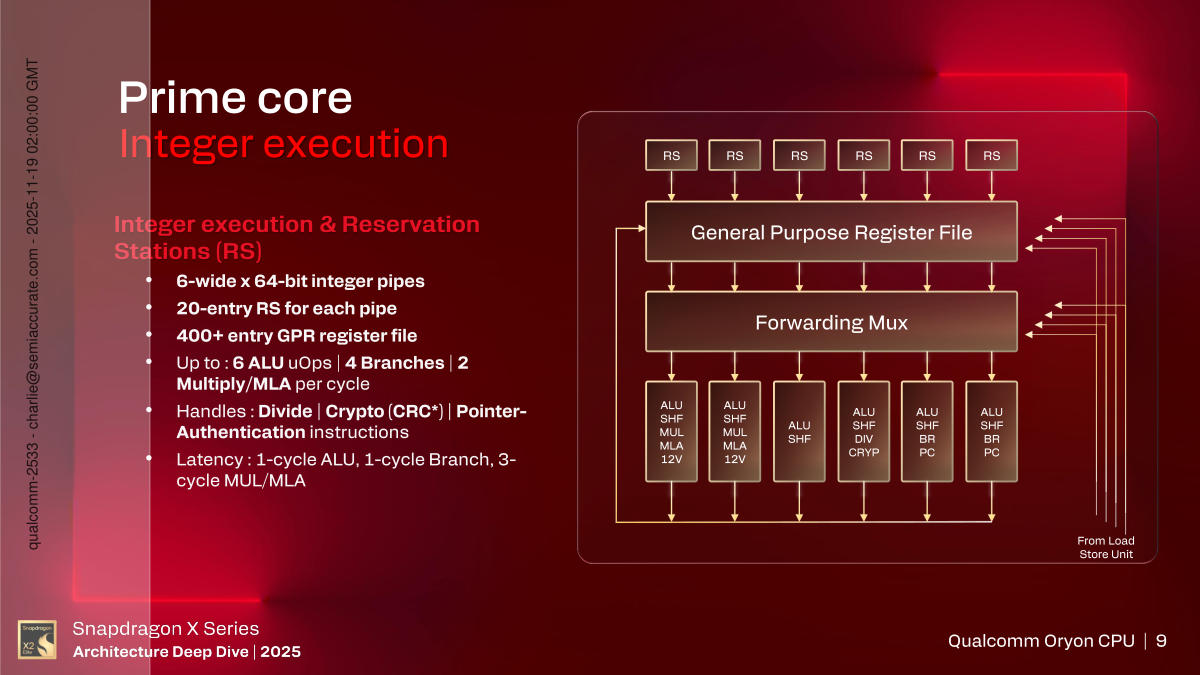
Prime Core Integer Pipeline
Wanting on the integer execution pipeline, there are six as beforehand talked about. 20 entry reservation stations feed every pipe, then right into a 400+ entry reservation station, then muxed to the pipes. Quite than sort out the capabilities of every, simply look above and notice the latencies are one cycle for ALU ops and branches, three cycles for multiplies.
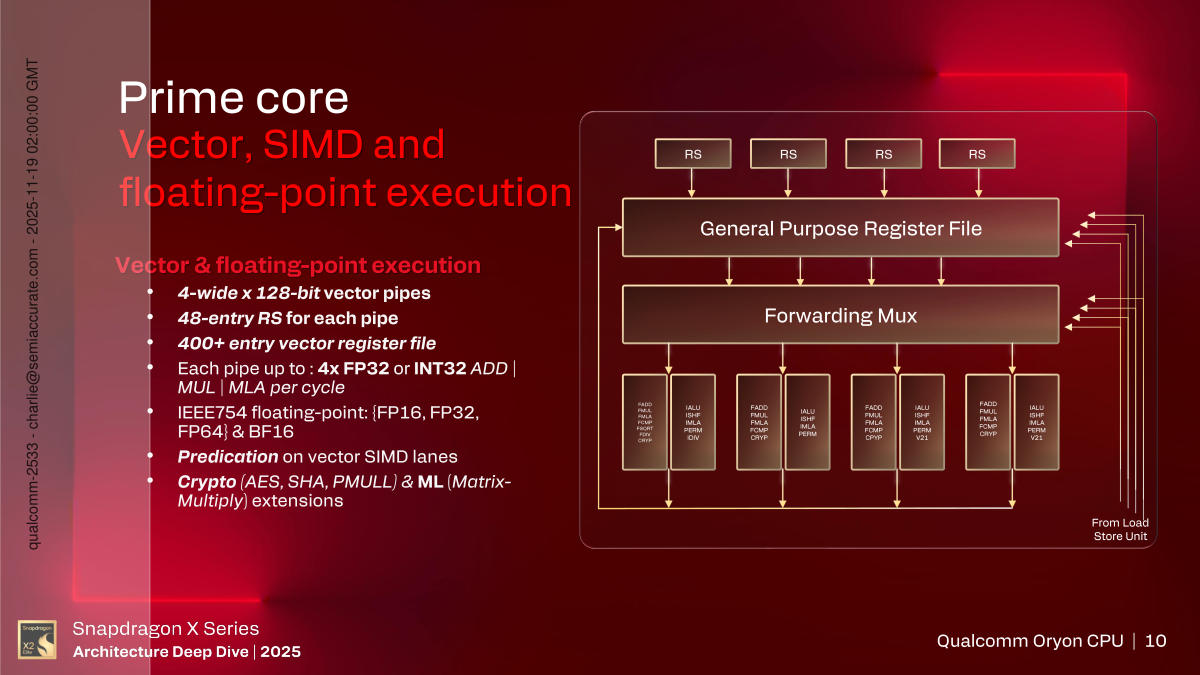
Prime Core FP and Vector Pipeline
As we talked about above there are 4 pipes for FP however every is 128b extensive versus the 64b width of the Int pipes. The reservation stations are a bit bigger at 48 entries which is comprehensible because of the nature of their work and certain larger however unspecified latencies. Every vector pipe could be break up into 4x 32b ops, supported by predication. There are additionally crypto and matrix multiply directions. See why the latencies could be a tad longer than the 1-3 cycles for the Int aspect?
That brings us to the Load Retailer Unit, which has it’s personal 96KB 6-way L1 cache, 64B coherency if you take care of such particulars. It would translate addresses for hundreds and shops and helps 4KB and 64KB granules. The 4 pipes can all do hundreds or shops in any mixture which isn’t distinctive however most trendy CPUs have a tendency to emphasise hundreds. For queues there’s a 192 entry load and 56 entry retailer. Qualcomm mentions superior prefetching methods however for apparent causes doesn’t go into the key sauce any greater than what was mentioned earlier.
On the MMU entrance it’s just about what you’ll count on beginning with web page sizes from 4KB to 1GB, bigger pages are chunked into 1GB items. Virtualization is now 2-stage so you may faux you’re in Inception if you are doing undocumented issues with VMMs. Joking apart this may be helpful if you’re foolish sufficient to run Home windows for actual work.
The TLB setup is rather less widespread with a devoted 256 entry 8-way TLB for every of the I$ and D$ however the L2 will get a devoted 256K 8-way. As you may count on the L2 TLB is slower, 2 cycles, whereas the L1 TLB can do the job in 1 cycle. There’s additionally {hardware} desk stroll assist for 16 requests in flight and might serve intermediate requests. That is to permit the 2-stage virtualization to work, it’s obligatory overhead.
Transferring on to the L2 cache it’s 16MB per cluster or 32MB for the 2 Prime core clusters, absolutely coherent, MOESI, and inclusive of the L1 caches. Since it’s tightly coupled with the cluster it runs at CPU clock frequency however don’t confuse this with the frequency the person cores run at. The cache serves six cores and the Matrix engine, extra on this quickly, and has a 21-cycle common latency. Every core can have greater than 50 directions pending on the cache and the cache itself can assist 220+ in flight directions. To make use of the outdated joke, we had been hoping for 223+. Sick of that one but? The cache could be partitioned and allotted to a thread or core for efficiency causes as most trendy CPUs are wont to do.S|A
That is Half 1 of a sequence. Half 2 could be discovered right here, Half 3 could be discovered right here, and Half 4 could be discovered right here.