
{kind=link}
Panmnesia studies as much as 5.3x quicker AI coaching and a 6x discount in inference latency in comparison with present PCIe and RDMA-based designs.
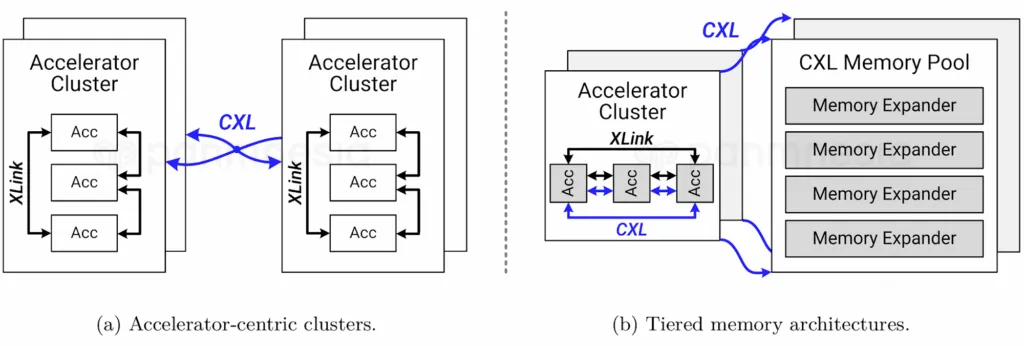
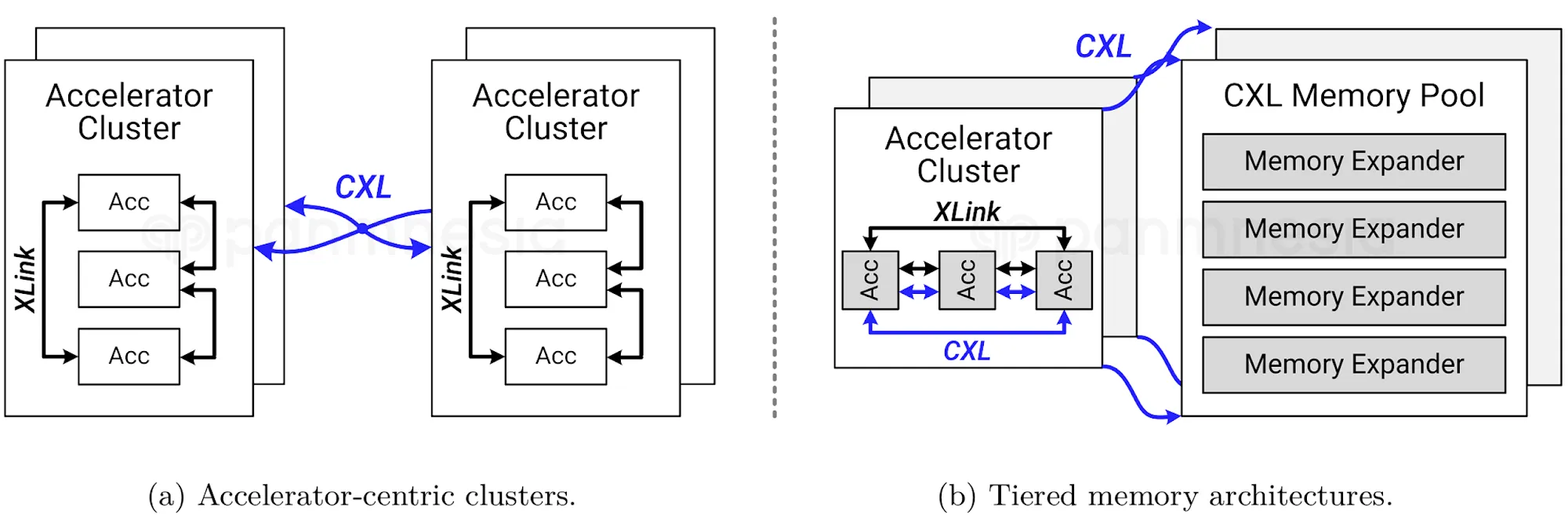
The structure allows a number of enhancements for scalable AI datacentres:
1. Compute and reminiscence could be scaled independently. GPUs and CPUs achieve entry to massive, shared swimming pools of exterior reminiscence through the CXL cloth, which eliminates the reminiscence bottlenecks of conventional architectures, particularly for memory-bound AI workloads. As a substitute of being restricted by the mounted reminiscence inside every GPU, workloads can draw on terabytes and even petabytes of reminiscence as wanted.
2. Composable Infrastructure: Sources—whether or not compute, reminiscence, or accelerators—could be dynamically allotted, pooled, and shared throughout disaggregated programs. This flexibility allows operators to adapt shortly to altering AI workload calls for with out pricey overprovisioning or {hardware} upgrades.
3. Decreased Communication Overhead: Through the use of accelerator-optimized hyperlinks for carrying CXL site visitors, Panmnesia’s structure minimizes the “communication tax” that plagues GPU-centric clusters, decreasing knowledge motion between distant nodes and maintaining reminiscence entry coherent and high-throughput. This results in considerably decrease latency (with CXL IP delivering sub-100ns latency) and elevated efficient bandwidth.
4. Hierarchical Reminiscence Mannequin: AI workloads profit from a brand new reminiscence hierarchy that mixes native high-bandwidth reminiscence (like HBM) with pooled CXL reminiscence, permitting environment friendly coaching and inference of huge fashions with out fixed swapping or bottlenecks.
5. Scalable, Low-Latency Switching Cloth: Panmnesia’s CXL 3.1 switches assist cascading and multi-level connectivity, so a whole lot of gadgets throughout many servers can entry reminiscence swimming pools and accelerators effectively, avoiding single-switch bottlenecks and enabling true scale-out AI materials