
{kind=link}

Robert Triggs / Android Authority
One other day, one other massive language mannequin, however information that OpenAI has launched its first open-weight fashions (gpt-oss) with Apache 2.0 licensing is an even bigger deal than most. Lastly, you’ll be able to run a model of ChatGPT offline and at no cost, giving builders and us informal AI fans one other highly effective software to check out.
As normal, OpenAI makes some fairly huge claims about gpt-oss’s capabilities. The mannequin can apparently outperform o4-mini and scores fairly near its o3 mannequin — OpenAI’s cost-efficient and strongest reasoning fashions, respectively. Nevertheless, that gpt-oss mannequin is available in at a colossal 120 billion parameters, requiring some critical computing equipment to run. For you and me, although, there’s nonetheless a extremely performant 20 billion parameter mannequin obtainable.
Are you able to now run ChatGPT offline and at no cost? Nicely, it relies upon.
In principle, the 20 billion parameter mannequin will run on a contemporary laptop computer or PC, offered you may have bountiful RAM and a strong CPU or GPU to crunch the numbers. Qualcomm even claims it’s enthusiastic about bringing gpt-oss to its compute platforms — assume PC moderately than cellular. Nonetheless, this does beg the query: Is it potential to now run ChatGPT completely offline and on-device, at no cost, on a laptop computer and even your smartphone? Nicely, it’s doable, however I wouldn’t suggest it.
What do you could run gpt-oss?

Edgar Cervantes / Android Authority
Regardless of shrinking gpt-oss from 120 billion to twenty billion parameters for extra common use, the official quantized mannequin nonetheless weighs in at a hefty 12.2GB. OpenAI specifies VRAM necessities of 16GB for the 20B mannequin and 80GB for the 120B mannequin. You want a machine able to holding the whole factor in reminiscence without delay to realize cheap efficiency, which places you firmly into NVIDIA RTX 4080 territory for enough devoted GPU reminiscence — hardly one thing all of us have entry to.
For PCs with a smaller GPU VRAM, you’ll need 16GB of system RAM if you happen to can cut up a few of the mannequin into GPU reminiscence, and ideally a GPU able to crunching FP4 precision information. For every thing else, comparable to typical laptops and smartphones, 16GB is absolutely slicing it high-quality as you want room for the OS and apps too. Primarily based on my expertise, 24GB RAM is required; my seventh Gen Floor Laptop computer, full with a Snapdragon X processor and 16GB RAM, labored at an admittedly fairly respectable 10 tokens per second, however barely held on even with each different software closed.
Regardless of it is smaller measurement, gpt-oss 20b nonetheless wants loads of RAM and a strong GPU to run easily.
In fact, with 24 GB RAM being ultimate, the overwhelming majority of smartphones can not run it. Even AI leaders just like the Pixel 9 Professional XL and Galaxy S25 Extremely high out at 16GB RAM, and never all of that’s accessible. Fortunately, my ROG Telephone 9 Professional has a colossal 24GB of RAM — sufficient to get me began.
The right way to run gpt-oss on a telephone

Robert Triggs / Android Authority
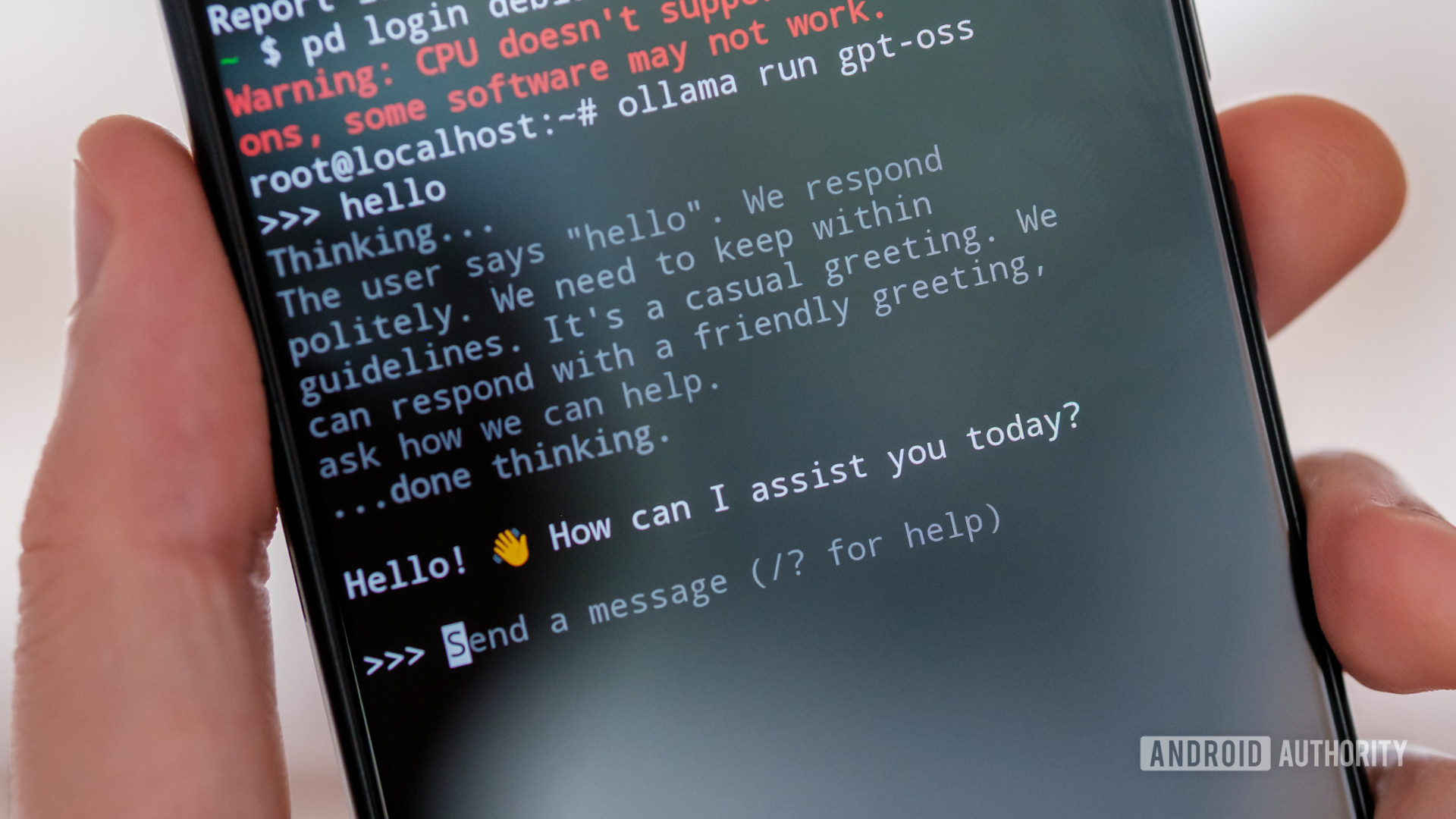
For my first try and run gpt-oss on my Android smartphone, I turned to the rising choice of LLM apps that allow you to run offline fashions, together with PocketPal AI, LLaMA Chat, and LM Playground.
Nevertheless, these apps both didn’t have the mannequin obtainable or couldn’t efficiently load the model downloaded manually, presumably as a result of they’re primarily based on an older model of llama.cpp. As an alternative, I booted up a Debian partition on the ROG and put in Ollama to deal with loading and interacting with gpt-oss. If you wish to observe the steps, I did the identical with DeepSeek earlier within the yr. The disadvantage is that efficiency isn’t fairly native, and there’s no {hardware} acceleration, which means you’re reliant on the telephone’s CPU to do the heavy lifting.
So, how properly does gpt-oss run on a top-tier Android smartphone? Barely is the beneficiant phrase I’d use. The ROG’s Snapdragon 8 Elite may be highly effective, however it’s nowhere close to my laptop computer’s Snapdragon X, not to mention a devoted GPU for information crunching.
gpt-oss can nearly run on a telephone, however it’s barely usable.
The token price (the speed at which textual content is generated on display screen) is barely satisfactory and definitely slower than I can learn. I’d estimate it’s within the area of 2-3 tokens (a couple of phrase or so) per second. It’s not completely horrible for brief requests, however it’s agonising if you wish to do something extra complicated than say hey. Sadly, the token price solely will get worse as the dimensions of your dialog will increase, ultimately taking a number of minutes to supply even a few paragraphs.

Robert Triggs / Android Authority
Clearly, cellular CPUs actually aren’t constructed for this sort of work, and definitely not fashions approaching this measurement. The ROG is a nippy performer for my day by day workloads, however it was maxed out right here, inflicting seven of the eight CPU cores to run at 100% nearly always, leading to a moderately uncomfortably scorching handset after just some minutes of chat. Clock speeds rapidly throttled, inflicting token speeds to fall additional. It’s not nice.
With the mannequin loaded, the telephone’s 24GB was stretched as properly, with the OS, background apps, and extra reminiscence required for the immediate and responses all vying for area. After I wanted to flick out and in of apps, I might, however this introduced already sluggish token era to a digital standstill.
One other spectacular mannequin, however not for telephones
Calvin Wankhede / Android Authority
Operating gpt-oss in your smartphone is just about out of the query, even when you’ve got an enormous pool of RAM to load it up. Exterior fashions aimed primarily on the developer neighborhood don’t help cellular NPUs and GPUs. The one manner round that impediment is for builders to leverage proprietary SDKs like Qualcomm’s AI SDK or Apple’s Core ML, which gained’t occur for this form of use case.
Nonetheless, I used to be decided not to surrender and tried gpt-oss on my growing older PC, outfitted with a GTX1070 and 24GB RAM. The outcomes had been positively higher, at round 4 to 5 tokens per second, however nonetheless slower than my Snapdragon X laptop computer operating simply on the CPU — yikes.
In each instances, the 20b parameter model of gpt-oss definitely appears spectacular (after ready some time), due to its configurable chain of reasoning that lets the mannequin “assume” for longer to assist clear up extra complicated issues. In comparison with free choices like Google’s Gemini 2.5 Flash, gpt-oss is the extra succesful drawback solver due to its use of chain-of-thought, very similar to DeepSeek R1, which is all of the extra spectacular given it’s free. Nevertheless, it’s nonetheless not as highly effective because the mightier and costlier cloud-based fashions — and definitely doesn’t run anyplace close to as quick on any shopper devices I personal.
Nonetheless, superior reasoning within the palm of your hand, with out the price, safety issues, or community compromises of at present’s subscription fashions, is the AI future I believe laptops and smartphones ought to really intention for. There’s clearly a protracted option to go, particularly in terms of mainstream {hardware} acceleration, however as fashions change into each smarter and smaller, that future feels more and more tangible.
A number of of my flagship smartphones have confirmed moderately adept at operating smaller 8 billion parameter fashions like Qwen 2.5 and Llama 3, with surprisingly fast and highly effective outcomes. If we ever see a equally speedy model of gpt-oss, I’d be way more excited.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.